stut-it Martin Stut - Information Technology Tailored to You
stut-it Martin Stut - Information Technology Tailored to You
By Martin Stut, 2017-01-30
If you are responsible for the Intranet of any kind of organization, you probably want to make sure that only authorized users know what’s written in there. But usually, unless you take measures described below, external sites are able to map out your Intranet. Most likely you do not want this mapping, because you are operating it as an Intranet for a reason.
This is how the mapping can work: It starts with Intranet pages containing links to external sites, e.g. news sources. Each time an Intranet user clicks on such an external link, the user’s browser will send a referrer field to the external web server as part of the HTTP request headers. This referrer field contains the URL of the (Intranet) page the link is placed in. This enables the external site to map your Intranet.
You might think that it is not a great deal if one external site knows of the existence of one internal page. But what if the collected referrer data of many large sites (think Dropbox and Facebook or a major newspaper) would be aggregated and sold to anyone willing to pay for it? Any interested party could get quite a large data set containing quite a detailed map about your intranet. You don’t want this, because you do place your information on an Intranet for a reason.
The news (maybe not so new to some interested groups) is, that this sale of data does happen. Companies like SimilarWeb do offer a lot of insight into the structure and visitors of websites. This includes where visitors are coming from, i.e. what site/page does link to the site being analyzed.
https://www.similarweb.com/ourdata indicates that they are getting (probably buying) data sets from several sources, Quoting from their web site:
The “panel of monitored devices” warrants a story by itself. Just look at news stories like this about the WebOfTrust browser extension. You basically need to assume that many user’s browsing histories are being collected and sold. Maybe I’m going to publish something about this issue in the near future.
The “direct measurement sources from websites” is what I’m caring about here.
As an example, I entered “ibm.com” into SimilarWeb’s search field. One of the results was “login.ng.bluemix.net” being one of their major referral sources. The domain name “login.(anything)” makes me think that this is a customers-only site. Nobody should know internal details of this. But still, when entering “login.ng.bluemix.net” into SimilarWeb’s search field, the topics tag cloud shows what it is about.
Maybe IBM is fine with the public knowing what login.ng.bluemix.net is about, but perhaps you would mind if the public knew this amount of details about your Intranet.
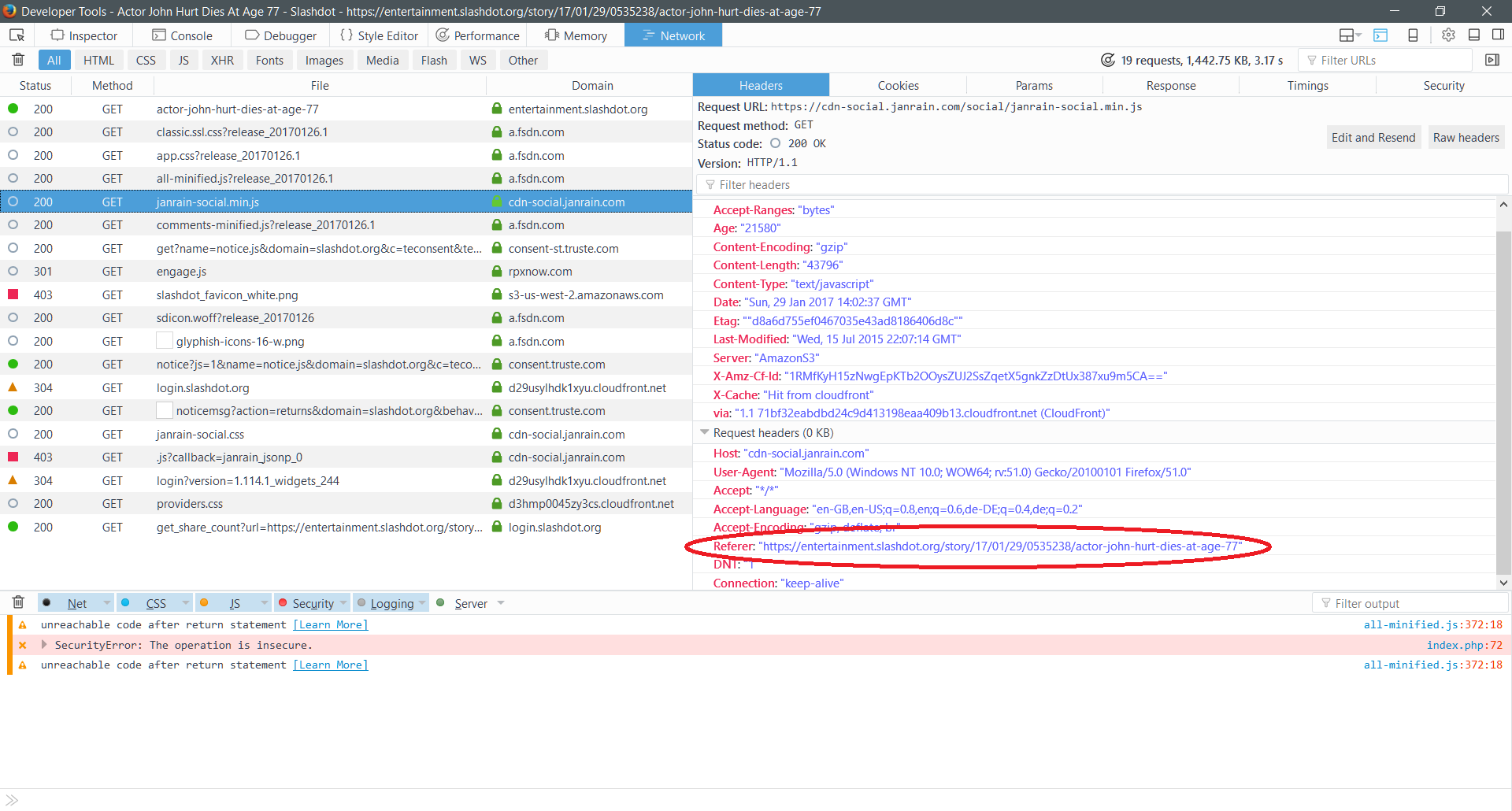
To verify the issue, I set up an mitmproxy in my home network and told my Firefox browser to use this proxy (full details would fill another blog post). (See addendum at the end of the post for a less technical method.) This enables me to see all HTTP(S) traffic of my browser.
At first I visited my Intranet start page http://www.home.stut.de , a static page only loading an additional local CSS file. The GET request for the CSS did contain the base address as Referer. This is no issue, since it stays local.
Then I visited http://www.home.stut.de/wordpress/ which is an almost emtpy test site, just to be able to get a feel for that platform. After GETting a bunch of internal files, Wordpress also fetched a Google Font and a Gravatar picture. This is where it got slightly scary: My browser did send the referrer http://www.home.stut.de/wordpress/ to Google and Gravatar. So Gravatar and Google now do know, and probably will tell SimilarWeb, that there is http://www.home.stut.de/wordpress/ .
Then I clicked on the link to the “Hello World” post, causing another GET from Google Fonts and Gravatar, this time with a referrer of http://www.home.stut.de/wordpress/hello-world/ .
Clicking on Categories / Uncategorized also sent a referrer to Google and Gravatar, this time http://www.home.stut.de/wordpress/category/uncategorized/ .
So my Intranet gets mapped by Google and Gravatar whenever I click on any internal link, because any internal page build generates a call to an external site. To me this is scary. This is an Intranet, not a public freebie blog platform.
In a nutshell: Stop visitor’s browsers from telling the referral URL to link target sites.
The World Wide Web Consortium is aware of the issue and working on a W3C Candidate Recommendation Referrer Policy major browsers are already implementing.
What you probably want is a Referrer Policy of “no-referrer” (never ever send a Referer HTTP header) or possibly “same-origin” (send the Referer header to your own site only, but no header to other sites) in case you need to track link flows within your Intranet. Some sources, e.g. https://html.spec.whatwg.org/multipage/semantics.html#meta-referrer , indicate that there is a legacy value of “never”, predating the definition of “no-referrer”.
Here are general alternatives of ways to deliver the referrer-policy to browsers, excerpted from §4 of W3C’s Candidate Recommendation Referrer Policy:
Referrer-Policy: no-referrer , for each page delivered.<meta name="referrer" content="no-referrer"> (Syntax taken from https://blog.mozilla.org/security/2015/01/21/meta-referrer/ )<a href="http://example.com" referrerpolicy="no-referrer">The official documentation is at http://httpd.apache.org/docs/current/mod/mod_headers.html
Before you start, you need to ensure mod_headers is enabled. On a Debian system, this command should do it:
a2enmod headers
In an appropriate configuration or .htaccess file, you need to place this directive:
Header set Referrer-Policy: no-referrer
On my Debian home server it did work this way:
/etc/apache2/conf-available/no-referrer.confa2enconf no-referrerPlacing the Header directive into a .htaccess file in the document root did have an effect only on the static pages inside the document root, but it did not have an effect on the /wordpress subdirectory. Wordpress still sent the internal referrer information to Gravatar and Google fonts. Only the server wide configuration file really did the trick.
Between the <head> and </head> tags of your web page or page template, insert this line:
<meta name="referrer" content="no-referrer">
You’ll need to do this on every single page that might contain links. This includes pages referring to web fonts, css files, JavaScript frameworks etc., so it can be a lot of effort - unless you have a template/content management system where you can do it in one place for all pages.
The alternative of adding a header line in a .htaccess file is better than having to do it in each page, but .htaccess files don’t always catch everything (see above).
Assume that your Intranet’s layout is probably already known to Google, SimilarWeb and their customers.
If this is not what you want, then you need to modify your web server’s configuration to ask your visitor’s browsers to not send Referer headers. Methods softer than modifying the Apache configuration most likely won’t catch everything.
A deep Linux admin friend wrote this response to this blog post:
If you’re not technical enough to use a mitmproxy, you can also use the developer tools in most browsers.